PDF-MSc Design and Analysis of Parallel Algorithms Supplementary Note Analysing Parallel
Author : ellena-manuel | Published Date : 2014-12-15
We then consider the complications introduced by the introduction of parallelism and look at some proposed parallel frameworks Analysing Sequential Algorithms The
Presentation Embed Code
Download Presentation
Download Presentation The PPT/PDF document "MSc Design and Analysis of Parallel Algo..." is the property of its rightful owner. Permission is granted to download and print the materials on this website for personal, non-commercial use only, and to display it on your personal computer provided you do not modify the materials and that you retain all copyright notices contained in the materials. By downloading content from our website, you accept the terms of this agreement.
MSc Design and Analysis of Parallel Algorithms Supplementary Note Analysing Parallel: Transcript
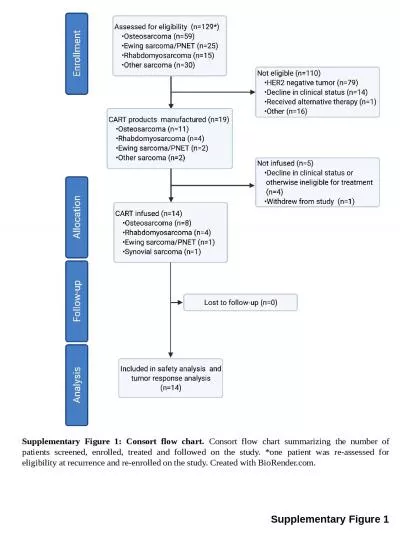
We then consider the complications introduced by the introduction of parallelism and look at some proposed parallel frameworks Analysing Sequential Algorithms The design and analysis of sequential algorithms is a well developed 64257eld with a large. G322 Exam – Section A. Analysing Representation. Gender . Age . Ethnicity . Class and status. Sexuality. Physical . ability/disability . Regional . identity . Analysing CLASS & STATUS. vs. Sequential Algorithms. Design of efficient algorithms. A parallel computer is of little use unless efficient parallel algorithms are available.. The issue in designing parallel algorithms are very different from those in designing their sequential counterparts.. Assume that we wish to compute. using the sequential instead of the batch algorithm. Given a set of initial conditions:. There is no . obs. at so we first do a measurement update.. Compute:. Conversion of the Sequential Filter into an Epoch State Filter. Yuri Gurevich. SOFSEM 2012. 1. The Czech . connection of “Gurevich”. z . Hořovice. . . von Horowitz . Horowitz . Horowicz. , . Hurwicz. . Гуреви. ч . . Gurevich. 2. Agenda. G322 Exam – Section A. Analysing Representation. Gender . Age . Ethnicity . Sexuality . Class . and status . Physical . ability/disability . Regional . identity . Analysing ETHNICITY. George Caragea, and Uzi Vishkin. University of Maryland. 1. Speaker. James Edwards. It has proven to be quite . difficult. to obtain significant performance improvements using current parallel computing platforms.. Andrew Lumsdaine. Indiana University. lums@osl.iu.edu. My Goal in Life. Performance with elegance. Introduction. Overview of our high-performance, industrial strength, graph library. Comprehensive features. Farida . Kassamnath. Anup Rawka. Motivation:. Sorting . is among the fundamental problems of computer science. Sorting of different datasets is present in most applications, ranging from simple user applications to complex software. Today, in this modern age, the amount of data to be sorted is often so big, that even the most efficient sequential sorting algorithms become the bottleneck of the application. It may be a database or scientific data. . 2. . Turing machine. . RAM (. Figure . ). . Logic circuit model. . RAM . (Random Access Machine). Operations . supposed to be executed in one unit time. (1). . Control operations such as. Lecture 8. Hartmut Kaiser. hkaiser@cct.lsu.edu. http://www.cct.lsu.edu/˜. hkaiser. /spring_2015/csc1254.html. Programming Principle of the Day. Principle of least . astonishment (POLA/PLA). The . principle of least astonishment is usually referenced in regards to the user interface, but the same principle applies to written code. . David Dayan, Moshe Goldstein, . Elad. . Bussani. Levy, Moshe . Naaman. , . Mor. Nagar, . Ditsa. . Soudry. , Raphael B. . Yehezkael. EuroPython. 2016. 1. agenda. Motivation. Objectives. EFL Programming Model. Algorithm is a step-by-step procedure, which defines a set of instructions to be executed in a certain order to get the desired output. Algorithms are generally created independent of underlying languages, i.e. an algorithm can be implemented in more than one programming language.. Consort flow chart summarizing the number of patients screened, enrolled, treated and followed on the study. *one patient was re-assessed for eligibility at recurrence and re-enrolled on the study. Created with BioRender.com.. Math. : This month we are learning to tell time to the nearest minute on an analog clock, find the area and perimeter of given shapes, and reviewing key math skills . in test prep activities. . Social Studies/Science.
Download Document
Here is the link to download the presentation.
"MSc Design and Analysis of Parallel Algorithms Supplementary Note Analysing Parallel"The content belongs to its owner. You may download and print it for personal use, without modification, and keep all copyright notices. By downloading, you agree to these terms.
Related Documents