

Ereira amp Rachel Bedder Methods for Dummies 201718 With thanks to Guillaume Flandin How do we correct for the multiple comparisons problem when making discrete observations of a highly spatially correlated image ID: 1034297
Download Presentation The PPT/PDF document "RANDOM FIELD THEORY Sam" is the property of its rightful owner. Permission is granted to download and print the materials on this web site for personal, non-commercial use only, and to display it on your personal computer provided you do not modify the materials and that you retain all copyright notices contained in the materials. By downloading content from our website, you accept the terms of this agreement.











1. RANDOM FIELD THEORYSam Ereira & Rachel BedderMethods for Dummies 2017/18With thanks to Guillaume Flandin
2. How do we correct for the multiple comparisons problem, when making discrete observations of a highly spatially correlated image?
3. How do we correct for the multiple comparisons problem, when making discrete observations of a highly spatially correlated image?Part 1Recap of t-statistics and alpha thresholdMultiple Comparisons ProblemBonferroni – why not?- Spatial DependencyPart 2Motivation for random field theory (RFT)Estimating smoothnessUsing RFT to threshold the SPM
4. NormalisationStatistical Parametric MapParameter estimatesGeneral Linear ModelRealignmentSmoothingDesign matrixAnatomicalreferenceSpatial filterStatisticalInferenceRFTp <0.05We are here
5. NormalisationStatistical Parametric MapParameter estimatesGeneral Linear ModelRealignmentSmoothingDesign matrixAnatomicalreferenceSpatial filterStatisticalInferenceRFTp <0.05We are hereWe need theseT-test
6. T-test recap
7. T-test recapNull hypothesis H0 No relationship between brain activity and task design matrix
8. T-test recapNull hypothesis H0 No relationship between brain activity and task design matrixTest Statistics Null T-distribution – calculated from degrees of freedom (n -1) t-statistic - evidence about H0 ua - accepted % of false positivest statistic = sample mean – population mean sample std / sqrt(n)
9. How likely is the t-statistic?Set significance level – alpha (a) Acceptable false positive rate Typically set at .05 (5%)
10. How likely is the t-statistic?Set significance level – alpha (a) Acceptable false positive rate Typically set at .05 (5%)P-value summarises evidence against H0 Probability of t (or greater) being observed given H0 cannot be rejected.
11. Multiple Comparisons ProblemFit one statistical model to each voxel60,000 voxels = 60,000 t-testsa = .05 (5%)Independent tests * a = 3000 false positives
12. Multiple Comparisons ProblemFit one statistical model to each voxel60,000 voxels = 60,000 t-testsa = .05 (5%)Independent tests * a = 3000 false positives
13. Types of Error-RatesPer comparison Controls probability of each observation being a false positive
14. Types of Error-RatesPer comparison Controls probability of each observation being a false positive Family-wise Error-Rate (PFWE)Controls probability of any false positives in a family
15. Types of Error-RatesPer comparison Controls probability of each observation being a false positive Family-wise Error-Rate (PFWE)Controls probability of any false positives in a familyFalse-discoveryControls ratio of true positives : false positives
16. Types of Error-RatesPer comparison Controls probability of each observation being a false positive Family-wise Error-Rate (PFWE)Controls probability of any false positives in a familyFalse-discoveryControls ratio of true positives : false positives
17. Multiple Comparisons ProblemBennett et al. 2009
18. Multiple Comparisons ProblemBennett et al. 2009 a = .00116/8064 active voxels One active cluster 81mm3
19. Multiple Comparisons ProblemBennett et al. 2009 a = .00116/8064 active voxels One active cluster 81mm3Using two multiple comparison corrections, no active voxels Family-wise error-rate False discovery rate
20. α = PFWE / nBonferroni Correctionsingle-voxel probability thresholdNumber of voxelsFamily-wise error rate
21. α = PFWE / nBonferroni CorrectionPFWE = .0560,000 voxelsa = .0000008single-voxel probability thresholdNumber of voxelsFamily-wise error rate
22. α = PFWE / nBonferroni CorrectionPFWE = .0560,000 voxelsa = .0000008single-voxel probability thresholdNumber of voxelsFamily-wise error rateAdjust threshold so finding any values above Ua are unlikely under the null hypothesis
23. Bonferroni Correction – too conservative!Individual voxels will not have independent t-statistics - scanner collects and reconstructs image - spatially correlated due to regional specificity - pre-processing increases spatial correlation
24. Bonferroni Correction – too conservative!Individual voxels will not have independent t-statistics - scanner collects and reconstructs image - spatially correlated due to regional specificity - pre-processing increases spatial correlationtherefore…No. of independent values < number of voxelsα = PFWE / ?
25. Spatial correlation - intuition10,000 random values from normal distributionHow many values are more positive than is likely by chance?
26. Spatial correlation - intuition10,000 random values from normal distributionHow many values are more positive than is likely by chance? Uncorrected a 0.05*10,000 = 500 false positives
27. Spatial correlation - intuition10,000 random values from normal distributionHow many values are more positive than is likely by chance? Uncorrected a 0.05*10,000 = 500 false positivesCorrected a .000005 = .05/10,0000.00005*10,000 = 0.05 <1 False Positive α = PFWE / n
28. Smoothing increases spatial dependencySmoothing: each value replaced by a weighted average of itself and its neighboursIncreased smoothingIncreased spatial correlation
29. Smoothing increases spatial dependencySmoothing: each value replaced by a weighted average of itself and its neighboursIncreased smoothingIncreased spatial correlation
30. Add spatial dependency (average across 10 x 10 squares)Bonferroni correction for 10,000 voxels now x100 too conservative!…but we don’t know how spatially dependent our data really is?
31. How do we solve spatial dependency problem?How smooth is the data?How many independent observations?
32. Random Field Theory: topological inference
33. Topological inferenceSet level inferencesIs the number of clusters significantly above chance?Cluster level inferencesIs the the spatial extent (volume) of the cluster significantly above chance?Peak level inferencesIs the peak of the cluster significantly above chanceWe’ll use this example today!spaceintensityttclusMore specificityMore sensitivity
34. How is RFT used?InputsDesired FWER Information about the topology (size, shape, smoothness)OutputStatistical threshold (e.g. t-stat, z-stat, etc.)
35. Smoothness: from voxels to “resels”SPM looks at the residuals from your model and estimates the smoothness of this random field
36. Smoothness: from voxels to “resels”
37. Smoothness: from voxels to “resels”
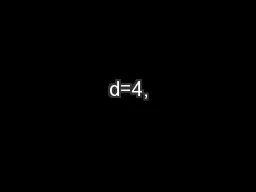
38. FWHMx = 3FWHMy = 3FWHMz = 3A Resel (Resolution element) is a block of values that is the same size as the FWHMR = search volume/smoothnessR = 10,000/(3*3*3) = 370.4Smoothness: from voxels to “resels”1 Resel27 voxels
39. What do Resels buy us?An approximation to the number of independent observationsBUT NOT IDENTICAL…YOU CAN’T JUST USE BONFERRONI USING NUMBER OF RESELSDon’t we already know the smoothness?No! There are other sources of smoothness, in addition to what we added ourselves. Smoothness: from voxels to “resels”
40. Thresholding the random field (the expected Euler characteristic)E[EC] = N(blobs) – N(holes)
41. E[EC] is an approximation of pfwe
42. Using RFT to find a threshold Set this to your desired pfweThe number of resels in your volumeOutput: The relevant threshold
43. AssumptionsError fields are a reasonable lattice approximation to an underlying random field(….with a multivariate Gaussian distribution, if using cluster-extent)These fields are continuous, with twice-differentiable autocorrelation functionAssumptions may not be met if:RFX analysis with small sample because result error fields might not be very smooth. Solutions:Subsample your voxels to increase smoothness?Use non-parametric method instead?Control FDR instead of FWER?YOUR CLUSTER-FORMING THRESHOLD NEEDS TO BE STRINGENT ENOUGH “A useful rule of thumb here is that if clusters have more than one peak, then the cluster-forming threshold is probably too low”
44. Assumptionsspacetcustcus
45. AssumptionsError fields are a reasonable lattice approximation to an underlying random field(….with a multivariate Gaussian distribution, if using cluster-exstent)These fields are continuous, with twice-differentiable autocorrelation functionAssumptions may not be met if:RFX analysis with small sample because result error fields might not be very smooth. You could subsample your voxels or use non-parametric method instead or control FDR?YOUR CLUSTER-FORMING THRESHOLD NEEDS TO BE STRINGENT ENOUGH “A useful rule of thumb here is that if clusters have more than one peak, then the cluster-forming threshold is probably too low”“A sufficiently high threshold is usually guaranteed with the standard cluster forming threshold of p = 0.001 (uncorrected)”(Flandin and Friston, 2017)
46. ResourcesAn introduction to random field theory (Brett, Penny and Kiebel, 2003)Topological inference (Flandin and Friston, 2015)Analysis of family-wise error rates in statistical parametric mapping using random field theory (Flandin and Friston, 2017)Previous MfD slidesMumfordbrainstats youtube channel