PPT-51 Use Cases and implications for HPC & Apache Big Data
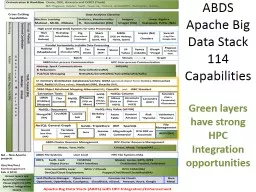
Architecture and Ogres International Workshop on Extreme Scale Scientific Computing Big Data and Extreme Computing BDEC Fukuoka Japan February 27 2014 3 Geoffrey
Download Presentation
"51 Use Cases and implications for HPC & Apache Big Data" is the property of its rightful owner. Permission is granted to download and print materials on this website for personal, non-commercial use only, provided you retain all copyright notices. By downloading content from our website, you accept the terms of this agreement.
Presentation Transcript
Transcript not available.