PPT-THE GENETIC CODE Genes contain the coded formula needed by the
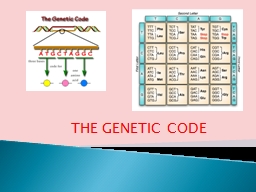
cell to produce proteins The sequence of nucleotides in a typical gene is a genetic code that carries the information for making an RNA The term genetic code refers
Download Presentation
"THE GENETIC CODE Genes contain the coded formula needed by t " is the property of its rightful owner. Permission is granted to download and print materials on this website for personal, non-commercial use only, provided you retain all copyright notices. By downloading content from our website, you accept the terms of this agreement.
Presentation Transcript
Transcript not available.