PDF-Failure rate Updated and Adapted from Notes by Dr
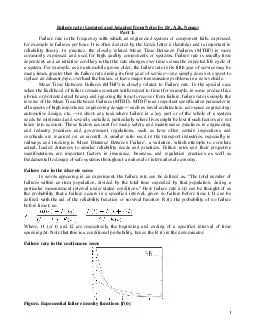
AK Nema Part 1 Failure rate is the frequency with which an enginee red system or component fails expressed for example in failures per hour It is often denot ed
Download Presentation
"Failure rate Updated and Adapted from Notes by Dr" is the property of its rightful owner. Permission is granted to download and print materials on this website for personal, non-commercial use only, provided you retain all copyright notices. By downloading content from our website, you accept the terms of this agreement.
Presentation Transcript
Transcript not available.