PDF-International Journal of Artificial Intelligence Appl
Author : pamella-moone | Published Date : 2015-05-30
4 No 4 July 2013 DOI 105121ijaia20134409 89 Alok Ranjan Pal 1 3 Anirban Kundu 2 3 Abhay Singh Raj Shekhar Kunal Sinha 1 College of Engineering and Management West
Presentation Embed Code
Download Presentation
Download Presentation The PPT/PDF document "International Journal of Artificial Inte..." is the property of its rightful owner. Permission is granted to download and print the materials on this website for personal, non-commercial use only, and to display it on your personal computer provided you do not modify the materials and that you retain all copyright notices contained in the materials. By downloading content from our website, you accept the terms of this agreement.
International Journal of Artificial Intelligence Appl: Transcript
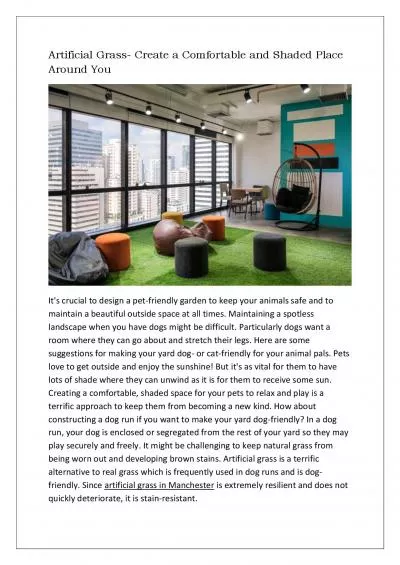
4 No 4 July 2013 DOI 105121ijaia20134409 89 Alok Ranjan Pal 1 3 Anirban Kundu 2 3 Abhay Singh Raj Shekhar Kunal Sinha 1 College of Engineering and Management West Bengal India 721171 chhaandasik abhaysingh3185 rajshekharssp kunalsa meer87gmailcom K. Jason Fuller. 1. What is Game AI?. Imitate intelligence in the actions of non-player characters (NPCs).. Make the game “feel” real.. Obey laws of the game. Show decision making . and planning. 2. Shuiwang. . Ji. General information. Instructor: . Shuiwang. . Ji. Office hours: Monday and Wednesday, 4:30PM-5:30PM, or by appointment. Office location: E&CS 3204. E-mail: . sji@cs.odu.edu. Research interests: machine learning, data mining, computer vision, computational biology. International Journal of Artificial Intelligence & Applications (IJAIA), Vol. 4, No. 5, September 201364 The structure of this paper is as follows: a review on how important to solve TSP and technique …and the mind-boggling stuff it can do. . THE MOST GENERAL DESCRIPTION OF AI. . A FANCY REPRESENTATION OF AI. FIRST PRINTING PRESS. FIRST AIRPLANE. LOOKING BACK IN TIME. Artificial Intelligence is a term coined by John McCarthy at the 1956 Dartmouth Conference.. Presented . by. :. . . Oliwual. . Islam. . . Vivek. . Mishra. . . Rahul. . Ravish. . and. . Machine Learning H. elp Create a . Military. . Operational Advantage?. . Offset Symposium. April 18-19, 2018. George Galdorisi. Strategic Assessments and Technical Futures Group. SPAWAR Systems Center Pacific. 1. Artificial Intelligence. AI – is a field of learning that emulates human intelligence. Advances in human intelligence:. Machine intelligence has led to Robotics. Space exploration. Medicine. Advanced research . to . rscheearch. at . Cmabrigde. . Uinervtisy. , it . deosn't. . mttaer. in . waht. . oredr. the . ltteers. in a . wrod. are, the . olny. . iprmoatnt. . tihng. is . taht. the . frist. and . 1. Artificial Intelligence. AI – is a field of learning that emulates human intelligence. Advances in human intelligence:. Machine intelligence has led to Robotics. Space exploration. Medicine. Advanced research . Year : . 20. 1. 3. . . LECTURE 07. First Order. Logic. 2. Introduction to First-Order Logic. Syntax and Semantics of First-Order Logic. Using First-Order Logic. Proof by Resolution. Knowledge Engineering in First-Order Logic. Chapter 10 New Frontiers for Ethical Considerations: Artificial Intelligence and Virtual Reality 1 Artificial Intelligence AI – is a field of learning that emulates human intelligence Advances in human intelligence: Are you sick of your property\'s overall appeal being harmed by a dull and neglected garden? In such a case, it could be time to think about including garden edging in your landscaping strategy. The advantages of purchasing an outdoor living area and offering practical advice for getting started. Why not make greater use of the room if you already possess it? Homeowners may design functional places for entertainment and leisure with the aid of outdoor living areas. It\'s crucial to design a pet-friendly garden to keep your animals safe and to maintain a beautiful outside space at all times. Maintaining a spotless landscape when you have dogs might be difficult.
Download Document
Here is the link to download the presentation.
"International Journal of Artificial Intelligence Appl"The content belongs to its owner. You may download and print it for personal use, without modification, and keep all copyright notices. By downloading, you agree to these terms.
Related Documents