PPT-CS440/ECE448 Lecture 8:
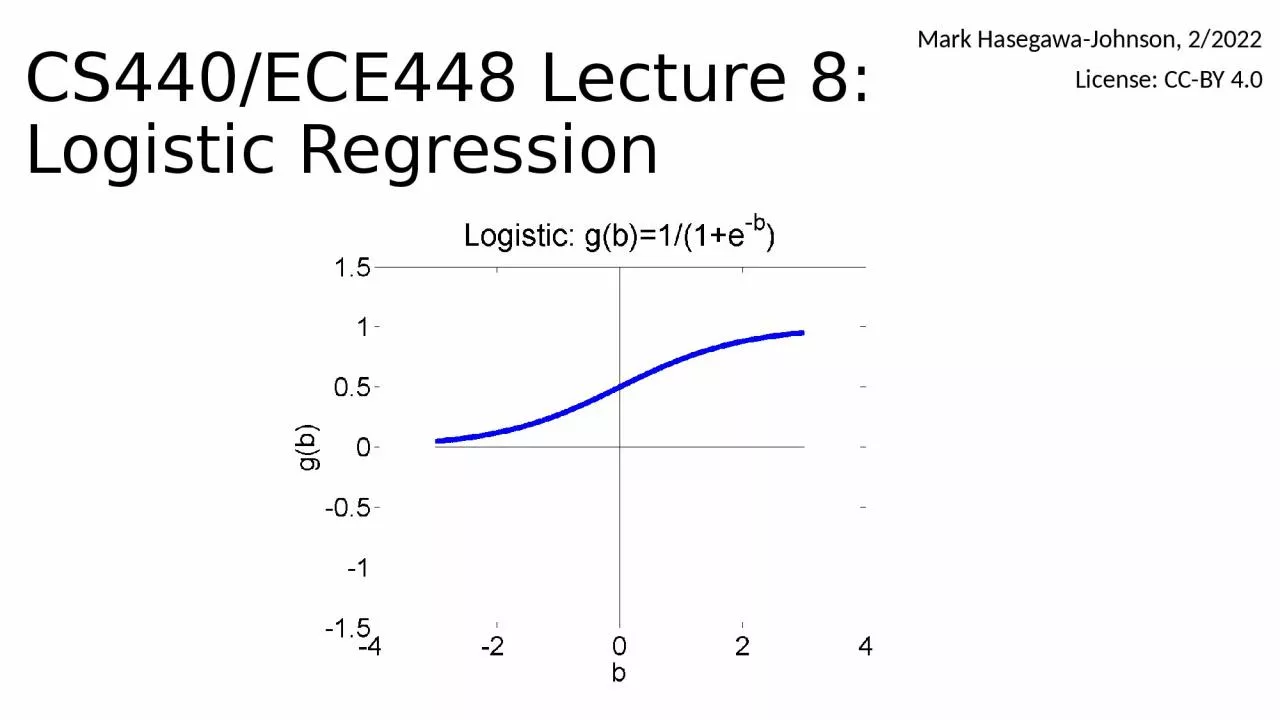
Logistic Regression Mark HasegawaJohnson 22022 License CCBY 40 Outline Onehot vectors rewriting the perceptron to look like linear regression Softmax Soft category
Download Presentation
"CS440/ECE448 Lecture 8:" is the property of its rightful owner. Permission is granted to download and print materials on this website for personal, non-commercial use only, provided you retain all copyright notices. By downloading content from our website, you accept the terms of this agreement.
Presentation Transcript
Transcript not available.